Trebuie sa inlocuiesc acel caracter unicode
?
sau
-
care tot apare in text cu un minus veritabil (ASCII), altfel nu vad ce trebuie.
Reformatez ca pentru mine, trimit si revin.
[Citat]
Am o intrebare legata de demonstratia "corectiei Bessel":
(sursa: Wikipedia)
Dupa ce am luat un esantion (sunt mai obisnuit cu termenii in engleza, nu stiu daca acesta este termenul folosit in matematica), luam la intamplare doua numere si le calculam patratul diferentei. Repetam pana ce epuizam numerele. Suntem siguri ca pentru n din cele n^2 perechi rezultatul a fost zero.
Pentru a calcula deviatia standard a populatiei din care am luat esantionul putem face acelasi lucru, doar ca acum N din cele N^2 perechi au avut rezultatul zero. Si cum N este foarte mare nu mai conteaza?
Multumesc.
|
A se vedea in primul rand:
http://en.wikipedia.org/wiki/Bias_of_an_estimator
(In acest articol se face si o trimitere la
http://en.wikipedia.org/wiki/Bessel's_correction
loc de unde sunt extrase cele de mai sus. A trebuit sa caut acest loc pentru a sti ce este de fapt de demonstrat.)
Problema de intelegere pe care o vad eu este urmatoarea.
Teoria probabilitatilor si statistica matematica se folosesc de aceeasi teorie a probabilitatilor, dar modul de lucru si de constatare al progresului este altul.
In teoria probabilitatilor luam de exemplu un sistem de variabile aleatoare cu aceeasi distributie si facem ceva cu ele. De obicei cerem sa fie independente, cu media m, varianta sigma², densitate data care este o functie de x real, m, sigma, ne legam apoi de legea numerelor mari, de teoreme limita centrale, de procese in care membrii sunt astfel de variabile, procesele primesc structura, incat sa implementeze o compatibilitate maxima in formule si manipularea lor cu valoarea medie conditionata....
In statistica, mai ales in statistica parametrica avem in prim plan cativa parametri, care sunt numere reale. Deci plecam de la numere reale si vrem sa facem un model cu ele si in model vrem sa le regasim cat mai des in locuri in care simtul comun ne dicteaza acest lucru.
Plecam deci cu doi parametri reali, m si sigma care sunt... mai vedem.
Acum vrem mai departe sa modelam ceva in interiorul matematicii.
Ne legam desigur paralel de doua lumi:
- lumea "a ceea ce putem observa"
- lumea "lucrurilor pe care le putem modela in teoria probabilitatilor cu sange rece".
Ca sa fiu mai explicit poate, incerc pe un exemplu. Nu este matematica, este doar o poveste:
Vine la controlul de calitate o valiza de suruburi pe care scrie "suruburi de 10mm, toleranta de 1%". Statisticianul care cumpara vrea sa verifice si face "observatii" si "estimari / estimatori (pe baza observatiilor facute)".
Un astfel de estimator este:
"Ia cateva observatii si fa media lor aritmetica".
Aici, media aritmetica este o functie generala MED de la "cateva" copii ale lui IR luate in produs cartezian la IR. Am scris cumva o variabila aleatoare? Nu. Cumva scriem totul folosind functii de la IR^? cu valori in IR.
Statisticianul chiar varsa suruburile din valiza pe jos, ia un pumn de suruburi, le masoara exact, si face media "pumnului de suruburi" folosind functia MED pe cele cateva masuratori.
Si se asteapta sa dea tot de "10mm cu toleranta de 1%". In fine, nu va da exact, probabil ca da de 9.9833333mm, dar de ceva da si crede sau nu ce e scris pe valiza.
Deci el inca are in prim plan parametri in statistica lui parametrica.
De exemplu, in ce mod calculeaza el abaterea ... Considerand ca media kilului de suruburi este 9.983333 mm, ca doar a luat un pumn de suruburi din valiza, sau considerand ca media este 10mm. (Statisticianul mai are si problema alegerii unei probe reprezentative de suruburi, dar asta e alta problema. In orice caz, doar trei suruburi nu pot fi considerate reprezentative, chiar daca au fost alese democratic de Partidul
In teoria probabilitatilor facem acelasi lucru, dar fara valiza si fara suruburi. Ne luam un spatiu de probabilitate "general" pe care nu l-am vazut niciodata explicit, un sir de variabile aleatoare independente si egal repartizate cu media fixa m si abaterea standard sigma, ne gandim ca putem face acelasi lucru pe care il face statisticianul cu functia lui "medie aritmetica".
Asadar aplicam MED pe cateva variabile aleatoare din sir, de exemplu
MED( X, Y, Z ) = (X+Y+Z)/3
daca X, Y, Z sunt primele trei variabile aleatoare din sir.
O prima intreare pe care si-o pune probabilistul pur este:
Care este valoarea medie in spatiul de probabilitate dat pentru MED( X, Y, Z )?
In termenii lui:
Sa se calculeze
IE[ MED( X,Y,Z ) ] .
Desigur ca dam de m.
Si acum vrem sa calculam ceva ce numim repede "varianta".
Cum calculam?
Probabilistul nu are probleme, trebuie sa scadem o medie din... pai nu avem decat media m la indemana, asadar o scadem si...
Statisticianul incepe in lumea lui reala a ceea ce observa sa isi puna probleme.
El poate sa scada *parametrul m* din statistica lui (luat pe post de medie), ceea ce scrie pe valiza ca este media, 10mm in cazul nostru cu suruburile, sau poate sa scada *estimatorul medie*, anume facand cele trei observatii, luand media lor. Daca in esantion am masurat
10.0923784
10.002378
9.998243789
atunci ceea ce corespunde strict la ceea ce face probabilistul este sa ne legam de estimatorul medie care este
( 10.0923784 + 10.002378 + 9.998243789 ) / 3
= 10.03100006300
Desigur ca este greu sa convingem un statistician sa foloseasca acest numar in loc de 10 [mm], cum scrie pe valiza pe care o verifica...
Exact din acest punct vine diferenta dintre ceea ce *vrem* in statistica si ceea ce *vrem* in probabilitati. Dupa ce scriem ceea ce vrem in fiecare din lumi in lumea in care putem sa gasim un numitor comun, anume in teorie, in teoria probabilitatilor ajungem la o relatie pe care o avem - legata de corectia Bessel. Demonstratia este elementara, un exercitiu simplu din teoria probabilitatilor. Demonstratia devine de neinteles doar daca o scriem in cuvinte. Cu cat scriem mai mult, cu atat trebuie citit si inteles mai mult. (Ca si cu mine de obicei.) Desigur ca la un moment dat ceva nu se intelege, statistica ne invata asa ceva, de aceea e bine sa scriem pe scurt. Scriind matematic relatii, fara a le povesti, dam de solutii simple si la obiect. In orice caz, si pe povestite, si pe partea pur calculatorie trebuie sa izolam mai intai ce trebuie sa demonstram. Dupa aceea totul este usor.
Dupa parerea mea, link-ul deja pomenit
http://en.wikipedia.org/wiki/Bias_of_an_estimator
explica foarte bine despre ce este vorba. Strict vorbind, nu poate fi vorba despre o "demonstratie a corectiei Bessel", ci de demonstratia faptului ca un anumit estimator este fidel / fara bias.


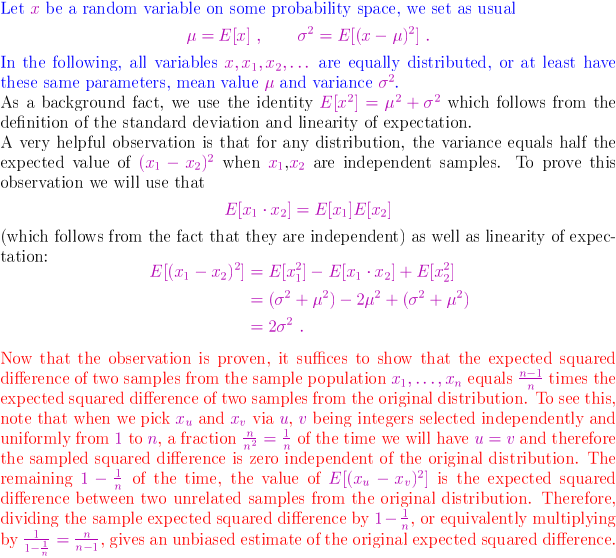
 Access general
Access general
 Conţine mesaje necitite
Conţine mesaje necitite